
Quantization is a technique used to reduce the size of machine learning models while maintaining accuracy. This can lead to faster deployment times, lower memory usage, and reduced bandwidth requirements when deploying these models on edge devices or in other resource-constrained environments.
What is Quantization?
The term “quantization” comes from digital signal processing where it refers to the process of converting an analogue signal into a discrete representation using finite precision numbers (bits). In machine learning contexts, quantization is used primarily for model compression and acceleration purposes.
There are two main types of quantizations: full-precision quantization and low-precision quantization. Full-precision models use the maximum number of bits allowed by hardware or software constraints (e.g., floating point numbers), while low-precision models reduce this precision to save space and improve performance at some cost in accuracy.
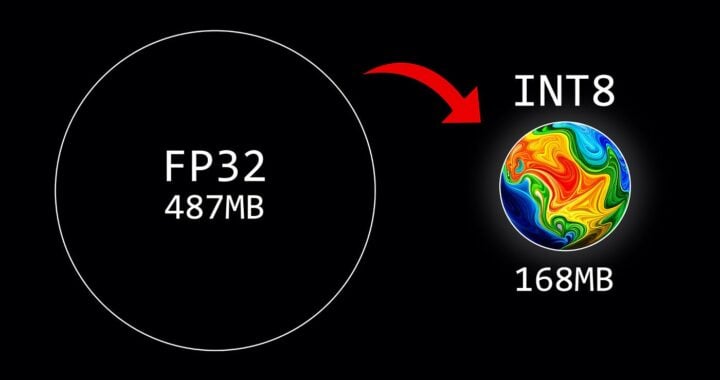
Quantizing a neural network involves replacing its weights with lower bit widths, such as 8-bit integers instead of 32-bit floats or even binary values (1’s and -1’s). This can significantly reduce the size of the model without causing too much loss in accuracy. The exact impact on performance depends on factors like the architecture of the neural network, its complexity, and how it was trained initially with full precision weights.
Quantization techniques have become increasingly important as machine learning models grow larger and more complex due to their resource-intensive nature during deployment. By quantizing these models, developers can make them compatible with devices that lack sufficient processing power or memory capacity for running large neural networks directly from RAM.
What are the labels with a Q and a number?
In terms of language learning model (LLM) quantization, different numbers such as Q2 through Q8 represent the number of bits used for precision during model training. The “Q” stands for “quantized”, and each level (e.g., Q4) indicates that there are four bits allocated to store values in a given layer or node within the neural network architecture.
The trade-off between quality and speed is an important consideration when quantizing models because reducing precision can lead to some loss of accuracy, especially if you go too low (e.g., using only 2 or 4 bits). However, this error may be negligible depending on your use case.
For instance, in natural language processing tasks like translation and summarization, where context is crucial but not always critical for correctness, small errors might still produce acceptable results without significantly impacting user experience.
Putting it all Together
When it comes to users running their own models, they should consider the following factors:
1) The specific requirements of your application – if high accuracy is needed even at reduced speed (or vice versa), then you may need to experiment with different quantization levels;
2) Hardware constraints – some devices might only support certain bit widths due to their architecture or memory limitations. In such cases, it’s essential to choose a level that fits within these bounds while still providing acceptable performance.
In summary, quantization allows developers and users alike greater flexibility in deploying machine learning models across various platforms by reducing model size without sacrificing too much accuracy. By understanding the trade-offs involved with different levels of precision (Q2 through Q8), one can make informed decisions about which level best suits their specific needs, whether they’re focused on speed or maintaining high quality output from their AI LLMs.